Update: Paris Traceroute bug from Early 2018
In December 2017, M-Lab was notified of oddities in the Paris Traceroute data, which we then wrote about in January 2018. Upon investigation, a bug in the Paris Traceroute code was identified. The bug caused bad measurement data in 2.7% of the traceroutes since July 2016.
The M-Lab team is doing development to work around the bug in several ways:
- By changing how we call Paris Traceroute to reduce the probability that the bug condition occurs.
- By adding more sophisticated bad data detection and elimination code to our parsing of Paris Traceroute data.
- By adding monitoring to our parser so that we can know how much of our raw data is affected at any given time.
- By reprocessing our historical raw data archives in order to eliminate all bad traceroute data caused by this bug from our BigQuery database.
The developers of Paris Traceroute reached out to us after our initial disclosure and created a version with that one bug fixed which can be found in the master 2 branch in the official repository. We are in the process of upgrading all our systems to this new version of Paris Traceroute.
Through disclosures and analyses like these, M-Lab re-confirms its commitment to open data and open science. Our raw data, warts, bugs, and all, is and will be always available, while our processed data continues to reflect our best understanding of the state of the Internet represented by that raw data.
Read More: The bug and its fixes
The root cause of the reported problem is a design flaw in Paris Traceroute, exacerbated by Rollins, the wrapper script that M-Lab uses to run it. The Rollins wrapper script went into production in first half of 2016 (replacing an older script which had its own flaws).
Every connection made to M-Lab systems triggers a Paris Traceroute to run from the M-Lab server back to the computer that initiated the connection. As the number of simultaneous traceroutes has increased, this has exposed a bug in Paris Traceroute where two independent traceroutes that overlap in time can become intermixed in the resulting Paris Traceroute output. For example, if we were to simultaneously run a traceroute from server S to clients A and B, the S-A path reported by the tool might contain hops that are exclusive to the S-B path, or it could switch in the middle of Paris Traceroute’s output from being the S-A path into being the S-B path.
In the following example, the output from Paris Traceroute switches without warning from being the output for:
$ paris-traceroute 35.188.101.1
into containing the data for the contemporaneously-run command:
$ paris-traceroute 139.60.160.135
The resulting output from the first command (shown below) shows a link that doesn’t exist from 216.239.51.185 to 173.239.28.18, on lines 8 and 9 and (worse!) switches without warning into the output from the second command (lines 9-13). In particular, note the suspiciously large RTT at the end of line 9 (4802.776/4803.621/4807.622/1.790 ms) which is also the point of transition from the S-A path to the S-B path.
traceroute [(173.205.3.38:33458) -> (35.188.101.1:40784)], protocol icmp, algo exhaustive, duration 14 s
1 P(6, 6) 173.205.3.1 (173.205.3.1) 0.138/5.405/31.541/11.688 ms
2 P(6, 6) xe-1-0-6.cr2-sjc1.ip4.gtt.net (89.149.137.5) 19.090/21.052/24.168/1.898 ms
3 P(6, 6) as15169.sjc10.ip4.gtt.net (199.229.230.134) 19.105/19.611/21.314/0.796 ms
4 P(6, 6) 108.170.243.13 (108.170.243.13) 19.872/20.275/20.931/0.446 ms
5 P(6, 6) 209.85.246.206 (209.85.246.206) 20.092/20.545/21.096/0.331 ms
MPLS Label 697177 TTL=1
6 P(6, 6) 209.85.248.127 (209.85.248.127) 53.493/54.490/57.796/1.493 ms
MPLS Label 638493 TTL=1
7 P(6, 6) 216.239.47.251 (216.239.47.251) 52.755/56.170/67.922/5.386 ms
MPLS Label 402431 TTL=1
8 P(6, 6) 216.239.51.185 (216.239.51.185) 52.455/52.652/52.981/0.228 ms
9 P(6, 6) csd180.gsc.webair.net (173.239.28.18) 4802.776/4803.621/4807.622/1.790 ms
10 P(6, 6) 173.239.11.1 (173.239.11.1) 66.509/66.524/66.561/0.018 ms
11 P(6, 6) 173.239.57.74 (173.239.57.74) 66.634/69.047/72.354/2.442 ms
12 P(6, 6) 139.60.160.1 (139.60.160.1) 67.066/70.367/72.034/2.327 ms
13 P(6, 6) 139.60.160.135 (139.60.160.135) 62.542/64.001/66.941/2.020 ms
This is obviously quite worrying, so the M-Lab team set about investigating why this is happening, how to prevent (or at least reduce the frequency of) its occurrence, and how to filter or annotate bad data in our database (while, of course, preserving the original raw data in our historical archives).
Paris Traceroute relies on a single 16 bit “tag” field to disambiguate returning ICMP messages.This single field is used both to identify which request packet (what initial TTL) and which session it belongs to. When there are two simultaneous tests, it is possible to have a collision of tag values, analogous to a hashtable collision. When one test starts first, that test runs for a bit, and then after the second (colliding) test starts, spurious data begins to arrive to the first test. The symptoms of this are that, in the middle of the first test, the results of the second test begin to pollute the results of the first. Just like with hash tables, the incidence rate of this bug scales up with usage. Sites with minimal numbers of connections saw no collisions, and sites with large numbers of connections saw an increased percentage of tests affected.
Based on the fact that the polluted test always ended up with the destination IP of a following test that started a few seconds later after the original test (but not necessarily the exactly next test after the original test), we calculated the impact of this bug for a single day, specifically, Dec 8th, 2017. The effect of this bug is about 2.7% of all tests across all M-Lab sites. But the distribution of polluted tests was not even across different metros. For smaller sites with less than 1000 daily tests, there were very few polluted tests. For the extremely popular metros like sea, atl, etc. the number of traceroutes affected went up. The most-affected sites are in the following table. We also look at the percentage of IP addresses affected, as wells as the number of tests affected. Some IP’s connected to M-Lab server’s quite a bit and are over-represented in the per-test data.
| site | % of affected tests | % of unique IP affected |
|---|---|---|
| mlab2.mil05 | 9.6%(630/6513) | 28.8% (15/52) |
| mlab3.sea03 | 8.9%(541/6101) | 25.8%(16/62) |
| mlab1.dfw05 | 7.3% 2841/39177) | 8.6% (2251/26210) |
| mlab1.atl05 | 6.5%(2572/39869) | 6.8% (2007/29379) |
| mlab1.iad05 | 5.5%(1759/32000) | 6.2% (1479/23743) |
Digging into the mlab3.sea03 data, where the percentage is very high and represented a strong outlier, we found that the bad traceroutes were not associated with any measurement tests or other legitimate traffic, but was instead due to simultaneous port scans and rumpelstiltskin attacks from two non-M-Lab IPs that happened to systemically collide inside Paris Traceroute. The unique IPs for that site is very small (62), and all polluted tests (16 unique IPs) were polluted by 4 unique IP pollution source.
Data of days in 2015, 2016 were processed for a historical check of problem incidence. The amount of data in previous years was significantly smaller that data in 2017. So when the sites were not as crowded as present, collisions were significantly less likely.
The impact of pollution dropped to 0% before Rollins. We also note in the table below, the deployment of Google OneBox’s NDT test integration as a significant event related to increased test volume around the same time, and note that it did not seem to have much of an effect.
| Date (one day sample) | # of affected tests | # of total tests | % of affected tests | Significant events |
|---|---|---|---|---|
| 2017/12/08 | 92889 | 3448373 | 2.7% | OneBox + Rollins |
| 2016/12/01 | 1993 | 139256 | 1.4% | PT drop due to servers down after Rollins |
| 2016/07/30 | 11924 | 494389 | 2.4% | After Rollins, before OneBox launch |
| 2016/03/02 | 0 | 382969 | 0% | Before Rollins |
| 2015/12/12 | 0 | 397984 | 0% | Before Rollins |
Using the insight that it is only a particular subset of IP pairs that are problematic, and that some IP addresses connect many more times than others, the traceroute bug was worrying in theory, but seems to be quite limited in practice.
Remediation
There are two main systems which, when combined, created the Paris Traceroute data in BigQuery. One is the Paris Traceroute codebase that runs on the server, consisting of the Paris Traceroute code and M-Lab’s support scripts that run on the server to support the running of that code. These combine to generate the raw data on the server, which is then saved to Google Cloud Storage. The next system is the ETL pipeline, which parses the raw data from Google Cloud Storage into queryable BigQuery tables.
To prevent the collection of bad data, we have created a workaround in our Paris Traceroute wrapper to bring down the expected number of incidents and that workaround will be deployed to M-Lab servers soon.
To prevent the inclusion of any bad data in our BigQuery tables, the ETL parser now can detect the polluted data (code) and discard them instead of inserting them into BigQuery. We also added monitoring to measure the error rates going forwards.
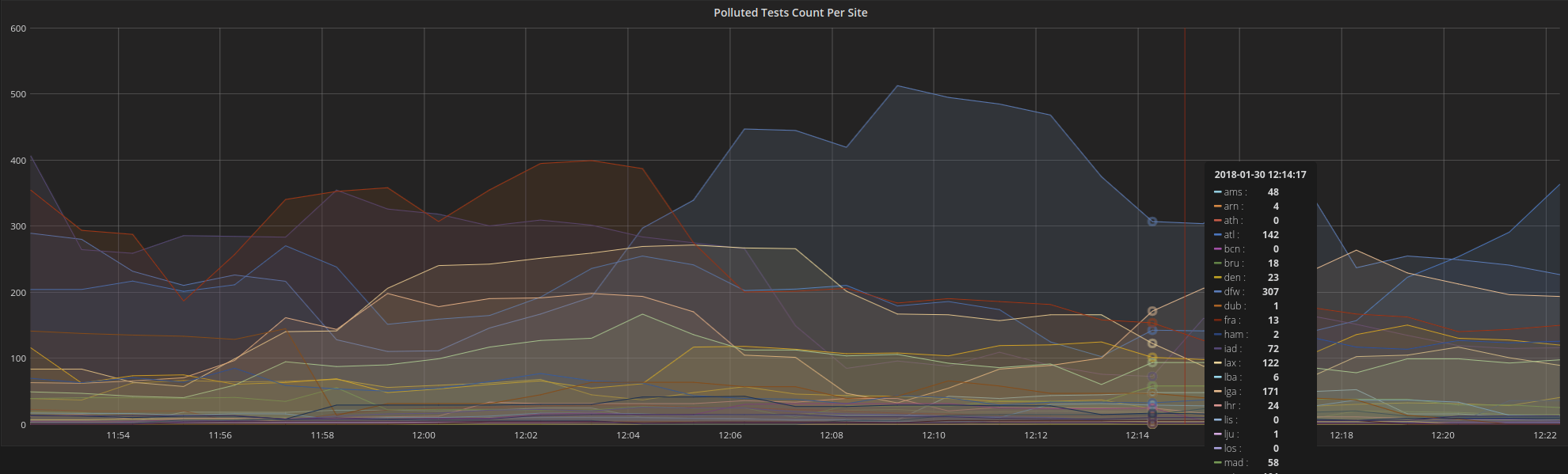 Figure 1: Number of polluted PT tests per metro
Figure 1: Number of polluted PT tests per metro
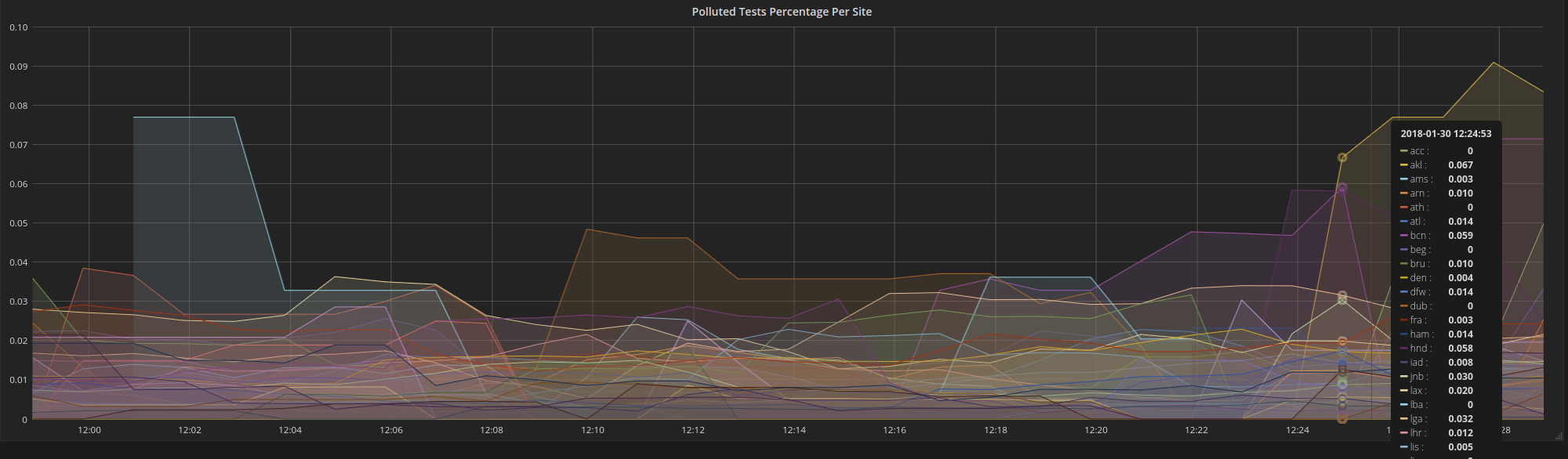 Figure 2: Percentage of polluted PT tests per metro
Figure 2: Percentage of polluted PT tests per metro
We will soon reprocess our historical archives. By the end of 2018 Q1, all affected PT data should be eliminated from our BigQuery database. M-Lab’s raw data will remain untouched, as our raw data reflects the data we actually got from M-Lab servers, not the data we wish we had gotten from M-Lab servers.
The Paris Traceroute Team has fixed the tag collision bug and their fix is available in the “master2” branch of the official repo. They fixed it by putting the PID of the PT process in the probe packet, and then ensuring that a PT process only considers packets which contain its PID in the returned headers. The new version is in the process of getting packaged up and rolled out to M-Lab servers.
In the future, this bug should not recur because it has been eliminated at the source. Nonetheless, we have augmented our wrapper scripts to reduce its occurrence, added monitoring to detect its reappearance, and we have added checks to our processing to help ensure that the bad data is not ever parsed into our BigQuery tables from our data archives old and new.