Evolution of NDT
NDT measures “bulk transport capacity”: the maximum date rate that TCP can reliably deliver data using the unreliable IP protocol over an end-to-end Internet path. TCP’s goal is to send data at exactly the optimal rate for the network, containing just the right mix of new data and retransmissions such that the receiver gets exactly one copy of everything. Since its creation, the TCP protocol has consistently made improvements to the way it accomplishes this task, consequently, NDT has also incrementally changed to reflect these improvements. The most recent improvements, including support for TCP BBR, are available in ndt7. On July 24th, we announced the start of migration of NDT clients to the latest protocol version. As of today, approximately 50% of clients are using ndt7. As the ndt7 measurements become the majority of the NDT dataset, the M-Lab team is considering what we do and do not know about whether and how changes to the NDT protocol have affected M-Lab’s longitudinal NDT dataset over time.
Over the long term we generally see an upward performance trend, almost everywhere, almost all the time. This trend is the consequence of multiple independent changes to the Internet and our platform:
- Upgrades to the Internet itself: faster links, more capacity;
- Upgrades and evolution of client connectivity: adding new fast users as others retire;
- Changes in how users self select;
- Upgrades to TCP;
- Upgrades to the M-Lab fleet, including faster uplinks and new locations, switches, servers and OSs;
- Upgrades to the measurement protocols, including moving to Websockets and BBR;
- Upgrades to the measurement tool implementations, both new clients and new servers;
Ideally, M-Lab would always measure just the Internet and always avoid coloring the data by our own infrastructure, but as a practical matter we can not do so perfectly. Instead, observe that none of this evolution is actually continuous. All changes affecting NDT have happened as a series of steps. Our belief is that it is possible to do A/B comparisons across each incremental change in order to preserve continuity of longitudinal data.
The rest of this post summarizes some of these changes to NDT and some of our open questions about their effect.
Timeline
Originally developed by Rich Carlson and the Internet2 team, M-Lab has hosted NDT since M-Lab began in 2009, and helped maintain and develop NDT for most of its history on the M-Lab platform. Over the last decade, there are three primary themes that have driven the evolution of NDT: standard kernel instrumentation, advances in TCP congestion control, and protocols and ports to support more clients.
The following table summarizes the changes in each protocol upgrade beginning with ndt3 in 2009.
 [1] Upload measurements use the TCP congestion control algorithm of the client.
[1] Upload measurements use the TCP congestion control algorithm of the client.
Changes in Kernel Instrumentation
In November 2019, M-Lab completed a platform upgrade that, amongst several other updates, enabled Linux standard TCP_INFO kernel instrumentation instead of web100 metrics. This instrumentation is what informs the detailed download, upload, and latency metrics that are reported to the user and publicly archived in the BigQuery dataset. Although web100 provided richer TCP instrumentation in some cases, it was not compatible with modern kernels, making it a barrier to upgrading the platform. By moving to TCP_INFO, we enable external reachers to exactly replicate our methods, and to track upgrades to TCP, including using TCP BBR in ndt7. For the most important instruments, web100 and TCP_INFO are identical. We are still investigating methods for estimating some of the historical web100 instruments from archived TCP_INFO data.
Open questions:
- Can we provide mappings of web100 data to TCP_INFO? If so, which metrics are the most significant to map?
- Every past and future kernel change affects some measurements. How do we weigh the value of staying current, relative to changes in the data?
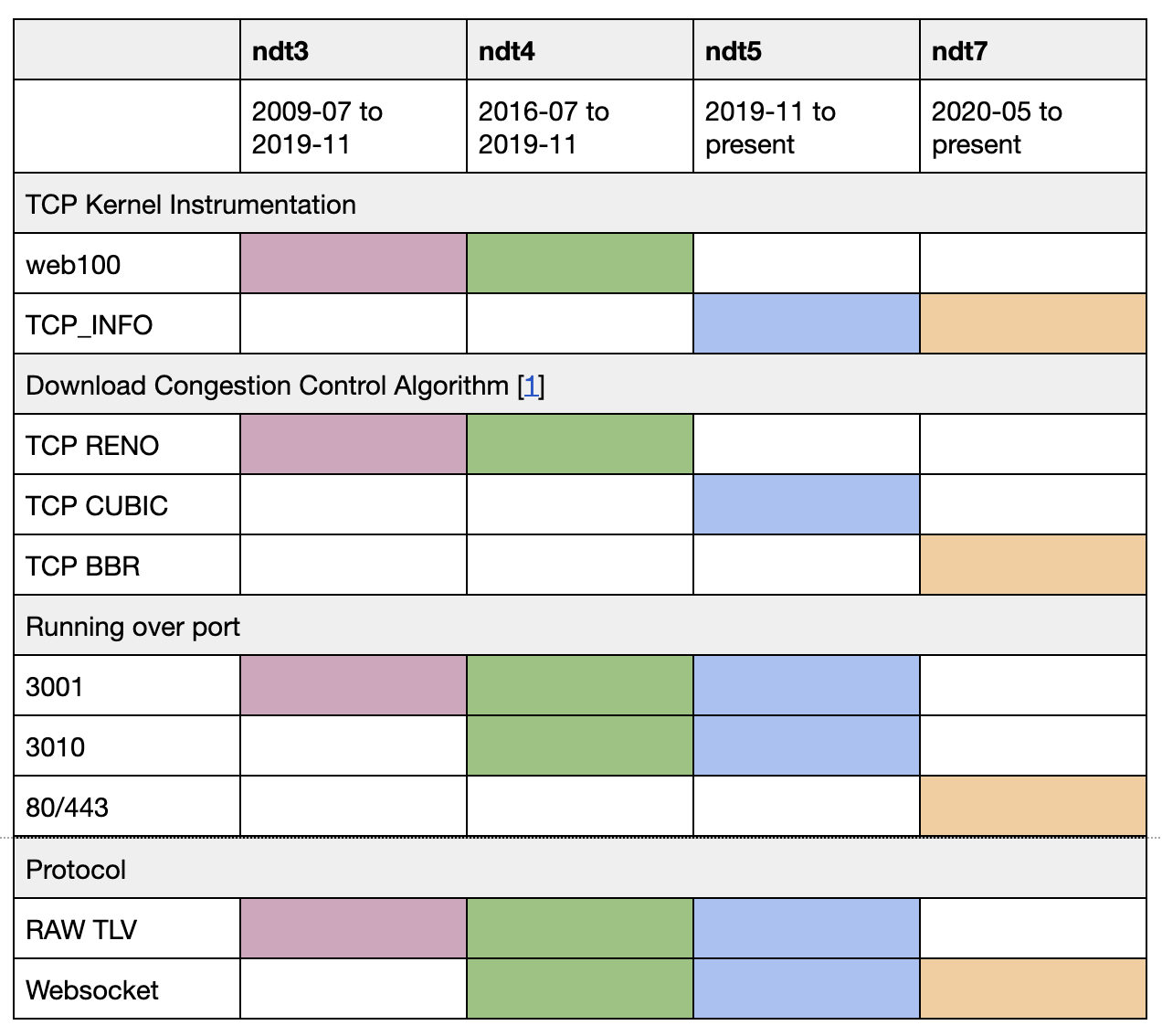
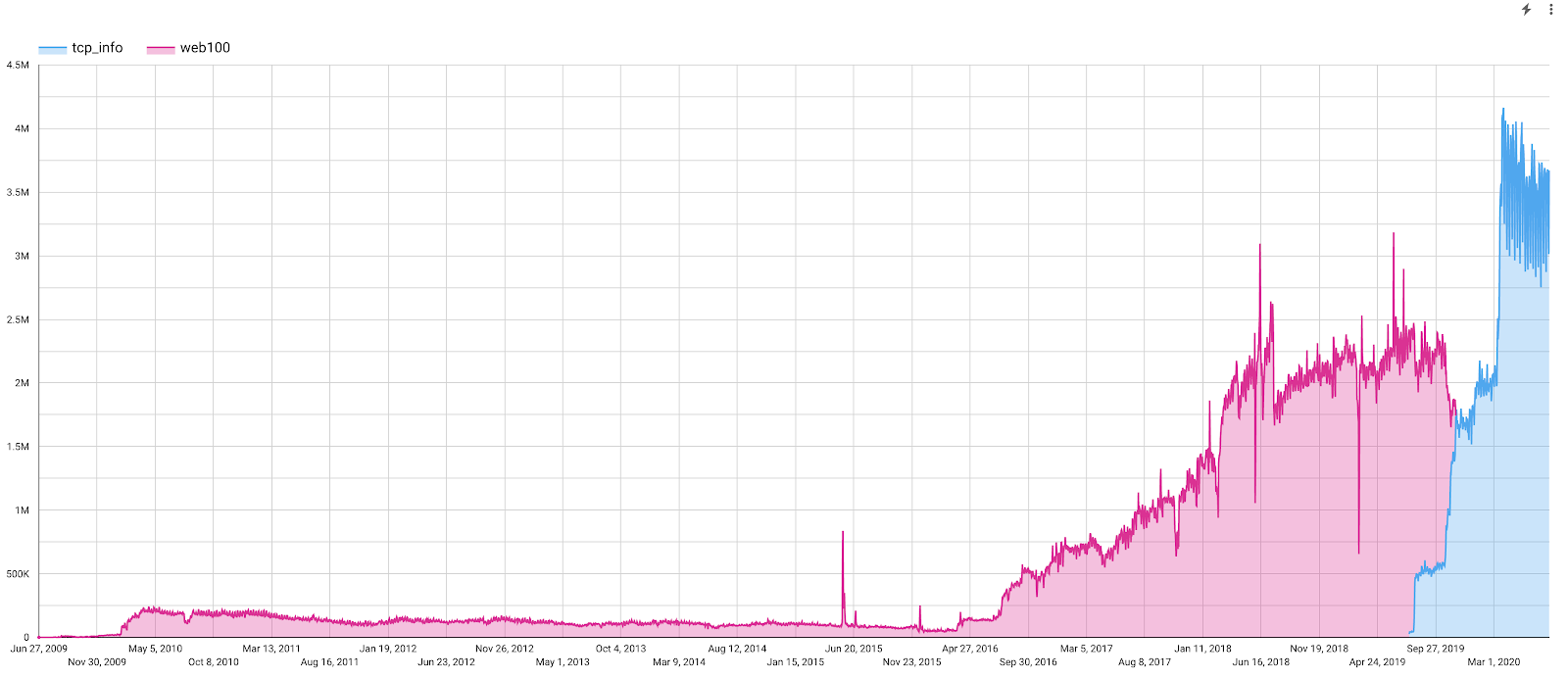 Figure 1: Instrumentation for NDT measurements started with web100 through 2019 when the platform switched to tcp_info.
Figure 1: Instrumentation for NDT measurements started with web100 through 2019 when the platform switched to tcp_info.
Changes in TCP Congestion Control
NDT uses TCP to measure the single-stream performance of a connection’s capacity for bulk transport, as defined by IETF RFC 3148. Single stream connections are the basic network building block for most applications. TCP performance is determined by the congestion control and recovery algorithms that govern data transmission. These algorithms use partial information about the state of the network to decide what data to send and when. The effectiveness of these algorithms determines TCP’s ability to efficiently fill the network.
Until 2019, all NDT measurements used TCP Reno, owing to the original NDT design. Since 2019, ndt5 has used TCP Cubic for all measurements. Earlier TCP routinely failed to fill the newest, fastest networks, adversely affecting application performance. Multiple streams is a common strategy to workaround legacy TCP performance limitations. TCP BBR overcomes many of these limitations. And, beginning in July 2019, we are supporting the migration of NDT clients to the ndt7 protocol, which uses BBR. In all cases, NDT faithfully reports client performance as a function of the version of TCP that it is based on. We are planning a future post on the impact of TCP evolution on M-Lab data.
Open questions:
- Under what conditions are TCP Reno (ndt3&ndt4) and TCP Cubic (ndt5) measurements comparable? TCP Cubic and TCP BBR (ndt7)?
- Can M-Lab’s BBR measurement be used to inform the wider community of its importance?
 Figure 2: TCP Congestion Control for download measurements used Reno until 2019 when the platform switched to Cubic by default. The ndt7 protocol uses BBR.
Figure 2: TCP Congestion Control for download measurements used Reno until 2019 when the platform switched to Cubic by default. The ndt7 protocol uses BBR.
Changes in Protocol and Ports
The original NDT server supported a single protocol (ndt3, aka “raw”) and used independent control (3001) and measurement ports (random) to orchestrate a download test. In 2016, M-Lab sponsored the addition of secure websocket support to the NDT protocol to support measurements from browsers (ndt4, aka “websocket”).
Like ndt3, the ndt4 protocol used independent control (3010) and measurement ports (random) running on non-standard TCP ports. The ndt5 protocol continued to support ndt3 and ndt4 clients to provide backward compatibility during the platform and kernel upgrade.
Unfortunately, in many environments, non-standard ports are blocked, which prevents NDT measurements. The new ndt7 protocol uses standard HTTP ports (80, 443) and a single TCP websocket connection for measurements. This simplification is expected to allow simpler implementations and measurements from more clients throughout the Internet.
Open questions:
- How do evolving web standards affect NDT measurements?
- How does the TCP port impact NDT measurements? e.g. due to network policies.
- How does the protocol impact NDT measurements? E.g. TLS, websocket.
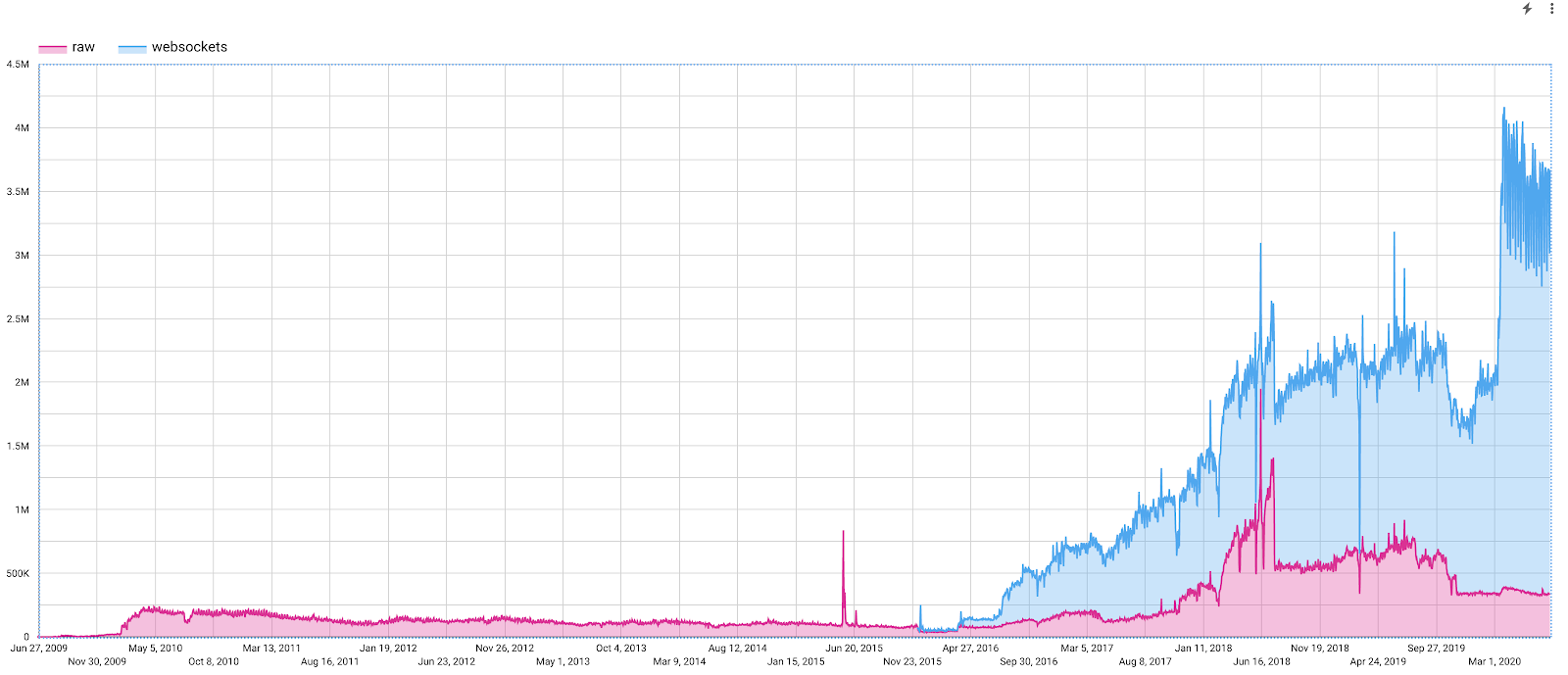 Figure 3: Until 2016, NDT clients used the “raw” protocol. In 2016, to access more clients through browsers, the websocket protocol was added to the NDT server. Websocket measurements are now the majority of test volume.
Figure 3: Until 2016, NDT clients used the “raw” protocol. In 2016, to access more clients through browsers, the websocket protocol was added to the NDT server. Websocket measurements are now the majority of test volume.
Future analysis & Community research
We are actively working on techniques to quantify the effect of each of these changes listed above and providing a mechanism to partially compensate for observable effects.
As part of the platform upgrade, we are building a new data pipeline to populate BigQuery from our archived raw data. This new pipeline will give us the capability to repeatedly reprocess archived raw data, and update the BQ data with additional annotations as we come to better understand the underlying phenomena affecting the data. Nearly all of the platform changes and some client changes are explicitly reported in the raw data and will (eventually) be fully exposed in BigQuery. We have the framework to label BQ rows with additional meta-data, for example per row calibration information which might be driven by heuristics based on platform changes.
Furthermore, our new pipeline will give us the capability to add user contributed annotations, for example to add heuristically derived node or measurement properties such as those described in Challenges in Inferring Internet Congestion Using Throughput Measurements or related unpublished works.
The new pipeline will also enable us to be completely transparent about how the data is (re)calibrated, and give data scientists choices about which calibrations they use. It will also permit analysis to be rerun under different calibration assumptions.
M-Lab is kept running by a small team of contributors with limited capacity. We will complete the most important parts ourselves, but are actively interested in external collaborators to help. If you would like to contribute, please contact us at support@measurementlab.net.